About a day after kicking off an intensive backfill process, the owning team noticed that it was taking longer than expected. When checking for bottlenecks, our metrics and monitoring tool highlighted some oddities around database read latency:
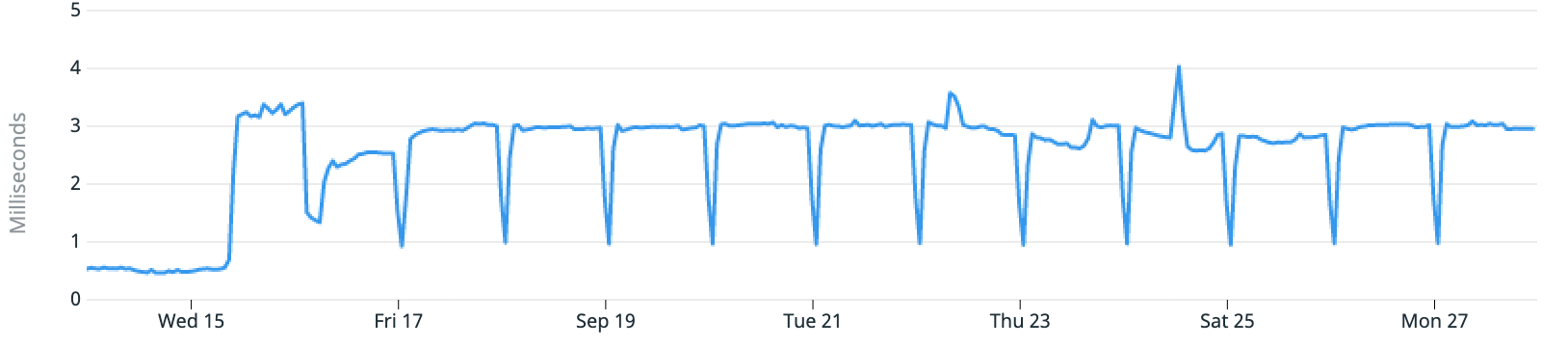
The average read latency of the database jumped from 0.5ms to 3ms, but briefly dipped down to 1ms every 24 hours. This didn’t match any application behaviour I would expect: if anything, I would expect an expensive query run daily to temporarily increase read latency.
Additionally, the database’s throughput metrics showed brief, sharp increases in read throughput correlating to decreases in read latency:
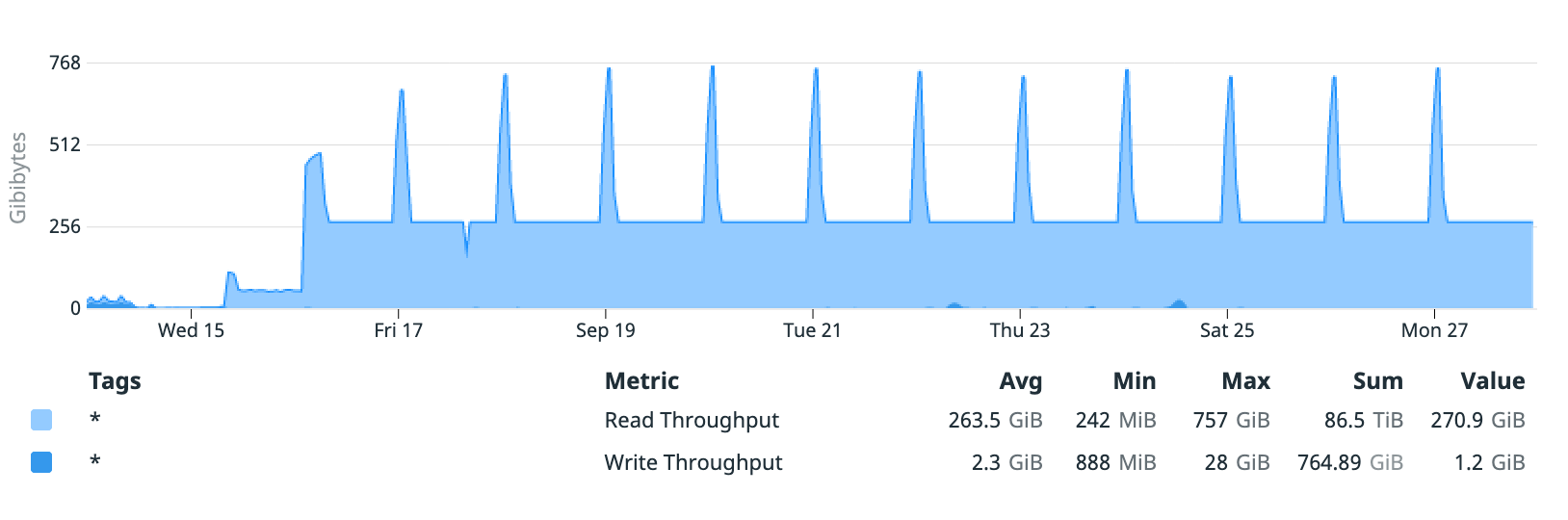
Based on previous experience, I expected this would be the result of an exhausted EBS burst balance - RDS DB instances rely on EBS storage for their storage requirements, and this database relies on gp2 storage.
EBS Burst Balances
EC2 instances (and by extension, RDS instances) almost always use EBS volumes for persistent data storage. EBS volumes are network-based, and apply various limits and thresholds to ensure fair service.
This particular database uses “general purpose 2” (gp2) storage. Volumes using gp2 storage only provision storage capacity, and IOPS/throughput scale based on that value. The IOPS and throughput limits will “burst” in some scenarios, allowing you to temporarily exceed the provisioned amount.
EBS gp2 Volume Calculator
The following calculator summarises the variable values based on the gp2 volume’s size. Calculations are based on information from AWS’s documentation, primarily Amazon EBS Volume Types and EBS I/O characteristics and monitoring.
Note that throughput limits are defined in MiB/s, or “mebibytes per second” — a mebibyte is 1,073,741,824 (1024³) bytes.
| Base | Burst | |
|---|---|---|
| Throughput | 187.5 MiB/s | 250 MiB/s |
| IOPS | 750 | 3000 |
| Duration | 40m | |
| Refill | 2h | |
EBS Volume Observations
In this scenario, the database used a 250 GiB gp2 EBS volume for storage. To summarise, this results in the following:
- 750 IOPS baseline, bursting to 3000 (for up to 40 minutes)
- 187.5 MiB/s throughput, bursting to 250 MiB/s (at time of writing, the volume would also be capped at 128 MiB/s if burst credits are exhausted)
When EBS burst credits are exhausted (as part of sustained load), read/write latency to the volume increases, as I/O operations beyond the baseline become queued (which additionally throttles throughput). I was surprised, however, to discover that most of the spikes did not involve an exhausted burst credit allowance:
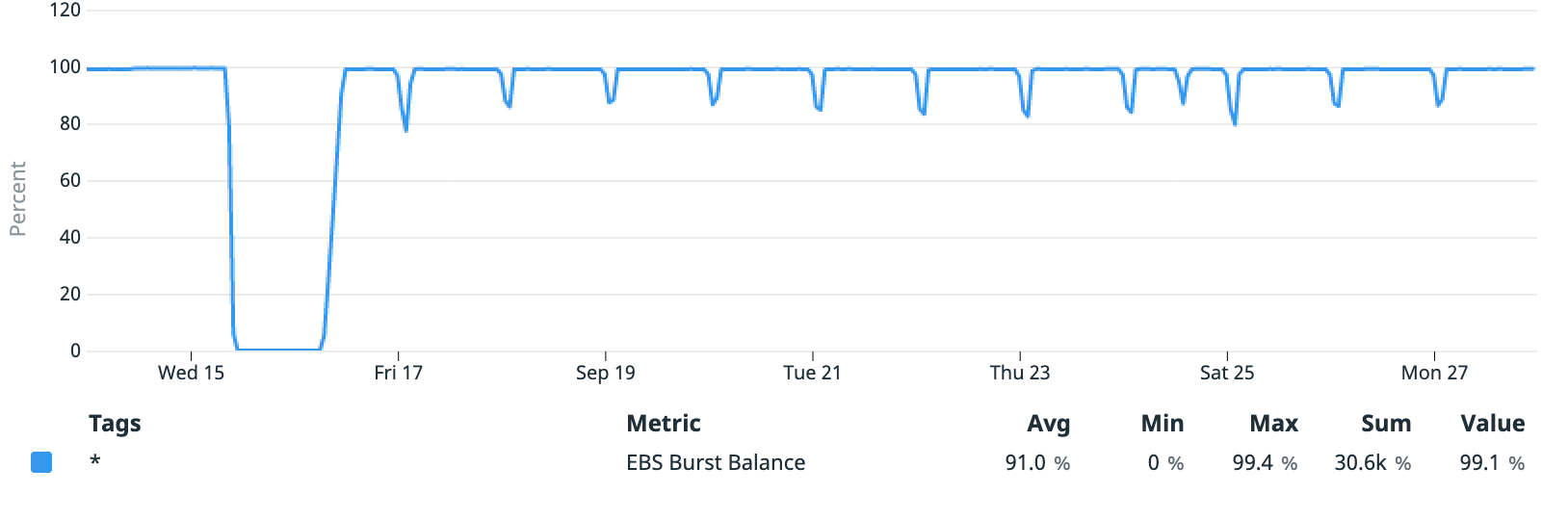
While the initial increase in read latency began with credit exhaustion, it mostly stayed at 100% beyond that point. It did, however, dip slightly with each decrease in read latency, which would suggest that some other factor was limiting I/O. Checking the database’s IOPS metrics:
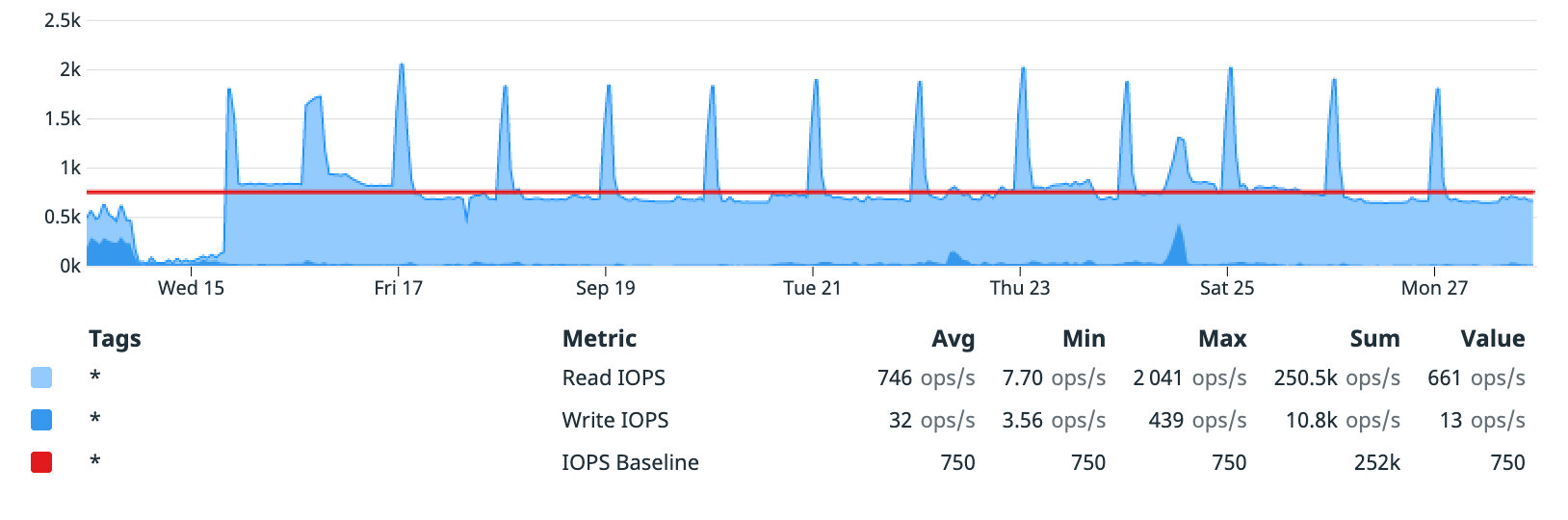
There’s a spike of increase I/O operations per second that align with the daily spikes of increased read throughput (and reduced read latency). Otherwise, the DB generally stays around the IOPS baseline allowed by the EBS volume.
Given these metrics, I concluded that the EBS volume was slightly under-provisioned, but not causing the performance degradation that prompted my investigation.
EC2 EBS Burst Balances
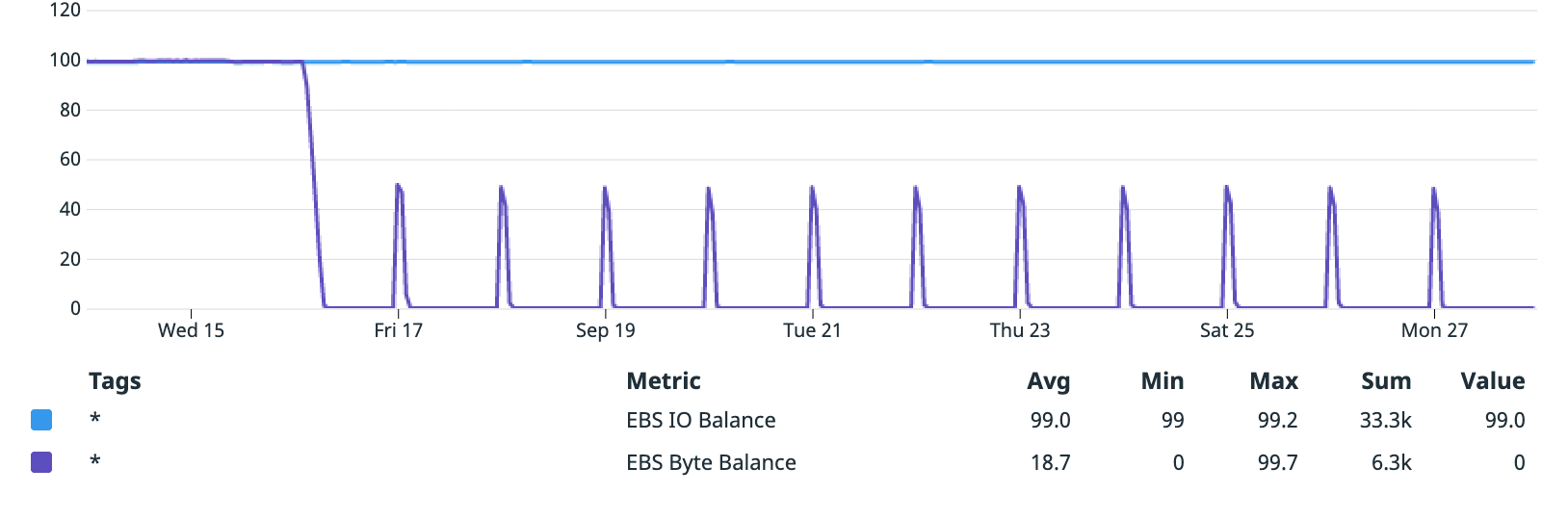
When checking the monitoring tab of the affected database, I noticed two EBS related metrics, both of which were unfamiliar to me. Notably, one of the metrics (EBS Byte Balance) seemed to correlate with the throughput and latency behaviour:
For reference, the database’s throughput metrics again:

The Amazon EBS-optimized instances page mentions these metrics, noting that they can be used to “help you determine whether your instances are sized correctly”. Looking further, I found a page detailing the available CloudWatch metrics for EC2 instances, which details these metrics:
EBSByteBalance%: the percentage of throughput credits remaining in the burst bucketEBSIOBalance%: the percentage of I/O credits remaining in the burst bucket
These metrics are associated with the EC2 instance, not with the EBS volume. Given the mentions of “throughput” and “I/O” credits, this takes us back to the Amazon EBS-optimized instances page. On this page, a table of details the maximum bandwidth, throughput and IOPS values for per instance size. For an m5.large instance (among many others), it also notes:
These instance types can support maximum performance for 30 minutes at least once every 24 hours. If you have a workload that requires sustained maximum performance for longer than 30 minutes, select an instance type according to baseline performance …
EBS Optimised Instances Comparison
For convenience, the following table compares EBS optimised limits across different instance types. Data is sourced from the AWS API, and can be cross-referenced via the Amazon EBS-optimized instances page.
Note that throughput limits are defined in MB/s, or “megabytes per second” — a megabyte is 1,000,000,000 (1000³) bytes.
| State | Throughput | IOPS |
|---|---|---|
m5.large | ||
| Base | 81.25 MB/s | 3600 |
| Burst | 593.75 MB/s | 18750 |
EC2 Instance Observations
In this scenario, the database is a db.m5.large instance. To summarise, this results in the following:
- 3600 IOPS baseline, bursting to 18750 IOPS
- 81.25 MB/s throughput, bursting to 593.75 MB/s
- Burst performance is supported “for 30 minutes at least once every 24 hours”
Overlaying the baseline throughput limit over the database’s throughput metrics shows an immediate connection:
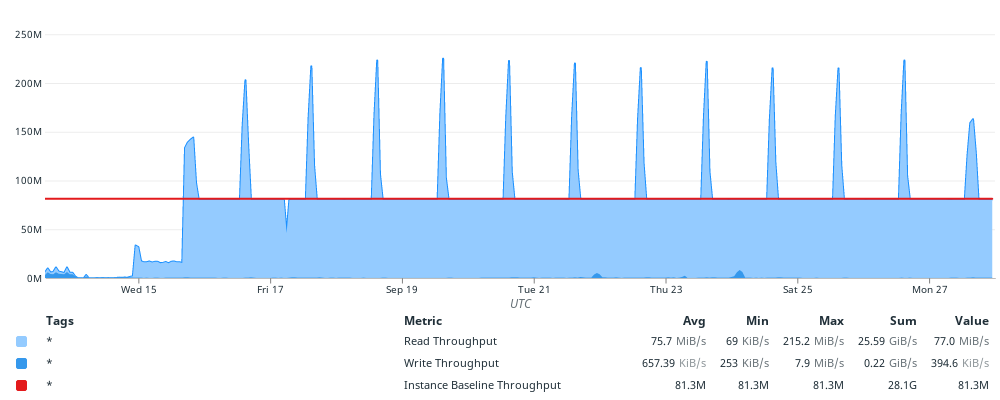
From that graph, I concluded that the database was consistently throttling on EBS read throughput, limited by the EC2 instance’s EBS throughput baseline. Additionally, the recurring brief spike in throughput occurs approximately every 24 hours, matching the maximum performance conditions mentioned by AWS.
Outcome
While the team owning the affected system eventually resolved the issue from another angle, this discovery highlighted some factors that previously had not been considered when sizing database instances. In particular, it indicated that determining suitable I/O performance requires a number of calculations, considering the intersection of EBS volume limits, and an EC2 instance’s “EBS Optimized” limits.
EC2 vs. EBS gp2 Volume Limits
This table displays the throughput and IOPS limits under various conditions for a specific EC2 instance size vs. a specific size of EBS gp2 volume. It may highlight bottlenecks in a given EC2 or RDS configuration.
| Burst | Throughput | IOPS |
|---|---|---|
| Instance & Volume | 262.14 MB/s | 3000 |
| Instance | 196.61 MB/s | 750 |
| Volume | 81.25 MB/s | 3000 |
| Baseline | 81.25 MB/s | 750 |