Complexity is a measure of anything related to the structure of a software system, that makes it hard to understand and modify the system.
In A Philosophy of Software Design, John Ousterhout notes that software development requires two skills:
- Creativity
- Ability to organise thought
As a result, he posits that a programmer’s biggest limitation is their ability to understand the system they’re working on. Based on the previous definition, this indicates complexity is in direct conflict with the skills necessary in software development.
Complexity is a natural component of software development. It’s unavoidable, but it can be managed and optimised. Well-designed systems carefully manage the effects of complexity, by balancing it overall.
Overall complexity can be approximated in mathematical terms:
In other words, the total complexity of a system is measured by totalling the “experienced” complexity of each part. The experienced complexity is represented by multiplying the complexity of each part, , by the amount of time developers spend working with that part, . Reducing one of these variables can have a multiplicative benefit on overall complexity. Conversely, if a part of the system is complex and also frequently modified, this results in an enormous increase of total complexity.
Adding features naturally increases the complexity of a system, so the overall complexity of a system grows over time. Managing the rate of growth is a key process for keeping well-designed systems.
Personally, I prefer to use “effective complexity”, as I feel overall may seem too precise. We’ve established that eliminating complexity is unnatural, so I feel better about managing effective complexity instead.
Managing complexity generally falls into one of two categories: eliminating or encapsulating it.
Eliminating Complexity
Reducing complexity of a part reduces overall complexity:
As the complexity of a part decreases, the effective complexity of the system also decreases.
For example, consider a user registration system, which enforces
unique usernames. If the logic which checks for uniqueness at
registration time
ignores character case (e.g. user1 == User1), users of the
system would generally assume that case does not matter when
providing their username to log in.
If the system that handles user login stores the username in a case-aware format in the database, the default query behaviour would require the user to specify the exact username they provided on registration, with matching case. In order to meet the user’s expectations, a developer could take steps to “normalize” the username, ensuring it is stored in a consistent format.
This approach introduces complexity throughout the system, as any code that uses this information must now ensure it performs the same normalization before comparing usernames. For example, if the system normalizes the username to lowercase, any search queries, login attempts etc. must also convert the provided username to lowercase, or it cannot match exactly.
If there were no requirements to compare usernames in a case-aware manner, then the developer could choose to adjust the data type in the database instead. Using a case-insensitive text type would prevent the system from performing a case-sensitive query. As a result, there would be no need to normalize the username within the system, and the complexity would be reduced. If all username comparisons occurred within the database, the complexity would be removed entirely.
Encapsulating Complexity
Encapsulating complexity reduces overall complexity when the process either:
- Eliminates complexity by untangling it into simpler modules, or
- Isolates complex behaviour into a part that’s less frequently touched.
Considering the previous definition of effective complexity:
As the time spent working with a part of the system decreases, the experienced complexity decreases. As effective complexity decreases, the overall complexity of the system decreases.
Applying this observation can reduce the effective complexity of a system even when removing the complexity is impossible.
As an example of unavoidable complexity, consider the series of steps that Slack uses to determine whether to send a notification to a user:
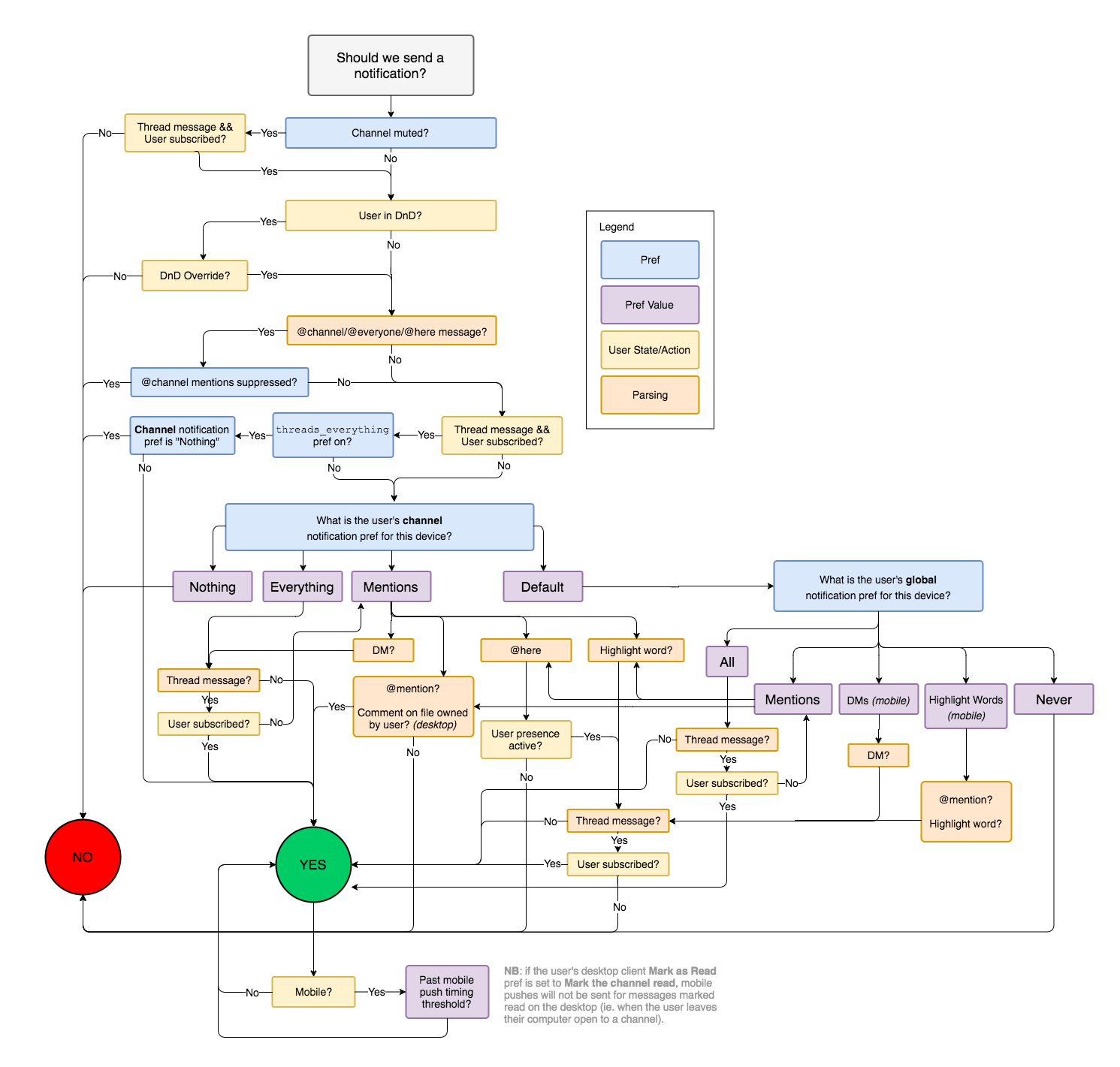
Slack’s workflow diagram encompassing all the considerations that go into whether to notify a user about a message, as of 2017.
(source)
The complexity of this decision is a direct product of the number of associated features. Unless “conflicting” features are removed, it is impossible to reduce the complexity itself.
When it is difficult to reduce the complexity of a part, it may be more productive to isolate the part instead, whilst recognising the contained complexity. If this is part is subsequently optimised for code stability, developers will spend less time experiencing the complexity.
From another perspective, it empowers the business to make better decisions about engineering effort. If introducing a new feature requires work in this complex part, it prompts the business to critically assess the value of the addition. If the complexity is spread throughout the system, then all work suffers from the complexity, and it becomes an invisible cost.